https://naver.me/F9Nbkx53

지도에 한반도 동쪽 바다를 표시한 뒤 챗GPT에 이름이 뭐냐고 영어로 물었습니다. 대답은 'sea of japan'.
다시 'east sea', '동해'가 아니냐고 묻자 일반적으로 'sea of japan'이라고 하지만 한국에서는 '동해'라고 한다는 답이 돌아왔습니다.
'삼국지'의 주요 인물이기도 한 조조가 고구려를 침략한 이유를 묻는 일종의 유도 질문에는, 실제 침략이 있었던 것처럼 말하더니 질문을 살짝 바꾸자 침략한 적이 없다고 고쳐 답했습니다.
GPT가 학습하는 데이터의 90%는 영어로 된 것으로 알려져 있습니다.
생성형 AI가 학습하는 데이터의 종류와 성격에 따라 편향적이거나 부정확한 답을 내놓을 수 있다는 뜻입니다.
미국 빅테크들이 개발한 AI 서비스에 장기간 노출될수록 단순한 기술 종속을 넘어 그 세계관에 물들 수 있는 위험이 존재합니다.
그래서 국가 고유의 역사와 문화, 사회를 이해하는 자국어 언어 모델을 비롯해, 자체 AI 학습 데이터와 인프라를 구축해야 한다는 '소버린 AI', 즉 'AI 주권' 개념이 주목받고 있습니다.

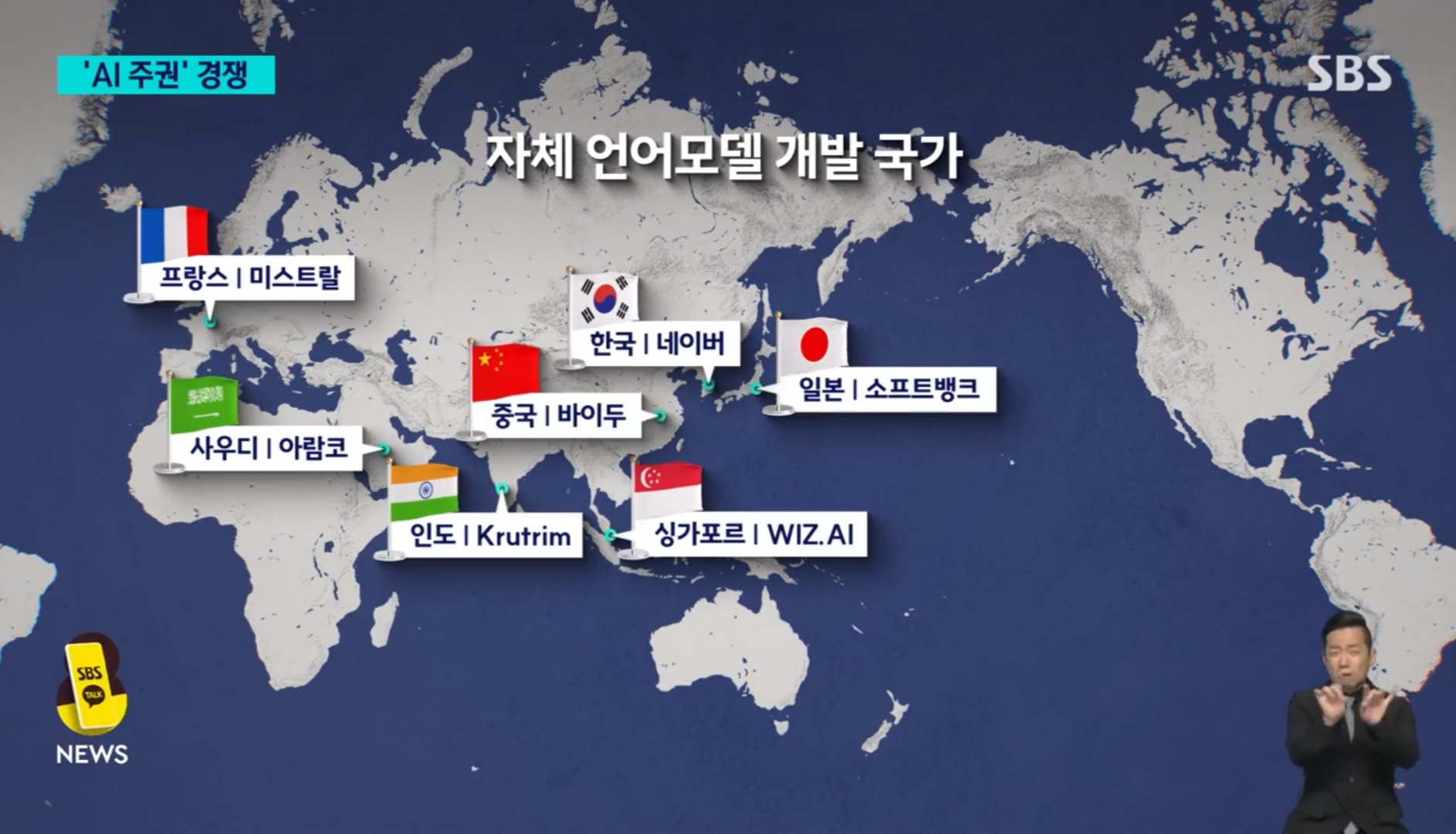
유럽 국가들은 물론 일본, 인도, 사우디, 싱가포르 등 각국이 정부 지원 아래 자체 언어모델 개발과 컴퓨팅 역량 강화에 나선 것도 이 때문입니다.

엔비디아 같은 AI 칩 개발 기업들은 빅테크에 이어 'AI 주권'을 지키려는 각국 정부의 AI 시스템 구축 수요가 새로운 성장동력이 될 것으로 기대할 정도입니다.

우리나라도 자체 언어모델을 개발하고 보강하는 IT 기업들의 투자와 함께, 정부의 정교한 지원 전략이 필요하다는 목소리가 커지고 있습니다.


